Acoustic Detection System (ADS) Final Status
The objective of WP6 in the TeamAware project is to develop an Acoustic Detection System (ADS) for search and rescue purposes.
The ADS is capable of detecting and localizing audible events for search and rescue purposes, including explosions/blasts, gunshots, human voices screaming for help or whistling.
An ADS mounted on a drone is particularly useful for first responders as it can access and survey areas affected by earthquakes, hurricanes, or terrorist attacks, which might be difficult for first responders to reach due to blocked roads and other obstacles.
Additionally, such an ADS can provide insights in scenarios where cameras may fail due to poor visibility or obstacles in the field of view. Moreover, the ADS can cue a camera system into a certain direction.
Therefore, a complete solution, with both an ADS and a camera system, has been implemented on the multi-copter drone and has successfully demonstrated its effectiveness.

The ADS is equipped with an Acoustic Vector Sensor (AVS) array for capturing the sound of the environment and utilizes a Raspberry Pi 4B to run all the algorithms.
Additionally, it includes a power bank for its power supply and a GPS dongle to provide real-time location tracking.
This compact and lightweight solution, along with a customized installation, was mounted on a DJI Matrice 300 RTK drone, enabling effective area monitoring.
A picture of the final system installed on the drone is illustrated in Figure 1.
In order to ensure that such a Search & Rescue multi-copter payload works both also with high noise levels, a novel sensor board has been designed.
On the one hand, a third acoustic particle velocity sensor element has been added.
By having different orientations, a possible high acoustic load will not “deafen” the sensor elements, ensuring the acoustic sensing capability remains available.
Such a concept can be expanded up to 12 acoustic particle velocity sensors, but, as the algorithms were designed for a maximum of 4 channels, the prototype has three particle velocity sensors.
Furthermore, a novel sound pressure transducer was used that has a high upper limit in its dynamic range.
In order to ensure that the ADS also performs in reverberant conditions where echoes will be present, the sampling rate of the AVS was increased to 48 kHz sampling rate.
For seamless integration with its surroundings, an Ethernet connection was designed for the ADS.
This connectivity feature not only streamlines data retrieval but also positions the sensor node as a versatile and integral component in various applications, including its envisaged role in the TEAMAWARE project.

As we are approaching to the final demonstration, it is with great excitement that we unveil a sensor node designed by Microflown AVISA, a leader in acoustic sensor technology. The AVS represents a significant leap forward in acoustic sensor design, poised to contribute invaluable insights in fields ranging from environmental monitoring to advanced drone-mounted acoustic arrays.
For outdoor acoustic sensing, in general wind caps are used. As the particle velocity sensors are extremely wind sensitive, a multi-layer wind-cap was developed based upon an acoustic foam, keeping the wind out and letting low frequency noise arrive at the transducers.
A sheet metal mounting was developed to install the ADS onto the Matrice 300 RTK platform.
A rubber ring, with a carefully optimized diameter, allows easy replacement and whilst ensuring tight sealing with the bottom mounting plate, ensuring optimal acoustic conditions.

To accomplish its objectives, the ADS developed by Microflown AVISA can host a range of algorithms developed by CERTH/ITI that can be used for both single and overlapping acoustic events.
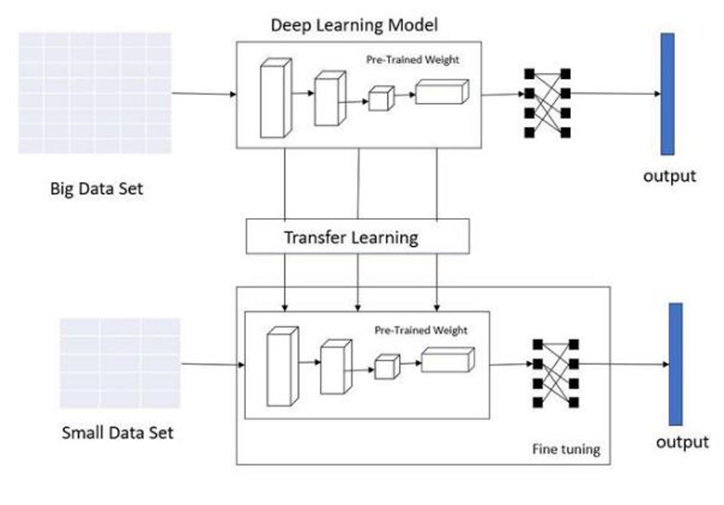
The methodological approach for the implementation of the sound event detection was the adoption of transfer learning which is a powerful technique and allows a model that has been pre-trained on a large and comprehensive dataset to be reused for a different but related task. This method is particularly beneficial when the dataset for the new task is smaller.
Because the model has already learned a considerable amount from the larger dataset, it requires less data to adapt to the new task.
As a result, the model can achieve high levels of accuracy without training complex models from scratch, saving time and computational resources.
The basic principle of the transfer learning is illustrated in Figure 5.
In this research, the YAMNet model, pre-trained on the AudioSet-YouTube corpus and utilising MobileNetV1 architecture, was employed using transfer learning. This model, trained on over 2 million audio events, was adapted to recognise eight specific sound classes relevant to our study. The high-level sound event characteristics from YAMNet were extracted and fed into a custom CNN model, which then processed these embeddings to identify the sound classes: Explosion, Glass Breaking, Gunshot, Background Noise, Screaming, Siren, Speech, and Whistle. To accommodate overlapping sound events, the model was engineered to consider the two most dominant classes in the probability distribution, thus enabling the simultaneous detection of multiple sound events. The architecture of the model is illustrated in Figure 6.

A robust dataset was created by combining publicly available data from FSD50K, NIGENS, MIVIA, URBANSOUND8K, LIBRISPEECH and specific data collected at CERTH premises. The duration of the final dataset is detailed in Table 1.

The trained model was evaluated on a separate portion of the dataset, specifically reserved for testing purposes in order to assess its performance on unseen data. The confusion matrix and the classification report of these results are illustrated in Figure 7 and Table 2 accordingly. The results demonstrated that the model achieved an overall F1-Score of 0.9435 on unseen data, indicating its strong recognition capability.
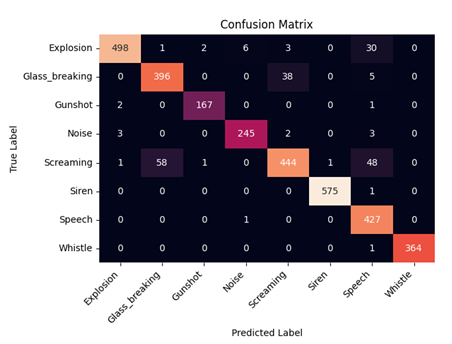
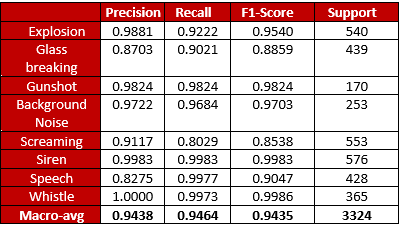
For sound source localization, we employed the widely-used GCC-PHAT algorithm. This algorithm is essential in signal processing for estimating the Time Difference of Arrival (TDOA) between signals received at different microphones. The technique robustly cross-correlates signals and prioritizes timing over amplitude by normalizing frequency components with a phase transform.
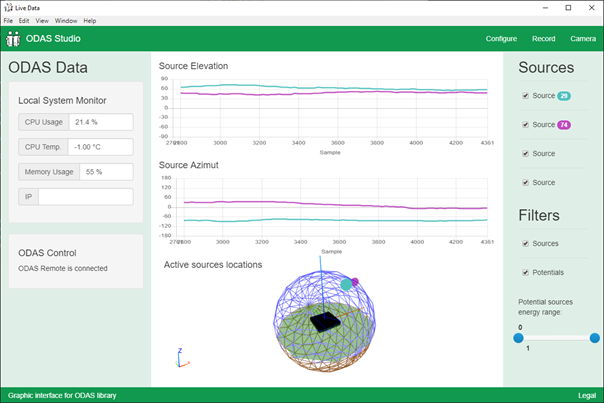
In this study, the GCC-PHAT method was specifically adapted to the AVS array, considering the topology of its channels. By combining TDOA data with the known speed of sound, the location of the sound source in space was determined. This process involves solving a nonlinear least squares problem to minimize the discrepancies between measured and hypothetical TDOAs. Calculating the Euclidean distance from the system's center and employing trigonometric calculations for azimuth and elevation enabled the estimation of the sound source's directionality in relation to the system, as depicted in Figure 8.
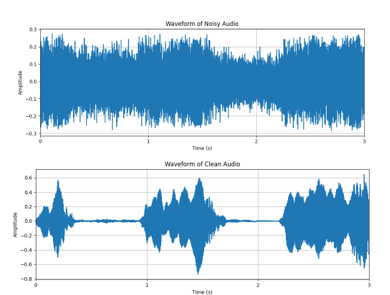
For the noise reduction a Dual-Signal Transformation Long short-term Memory (LSTM) Network was utilised. The DTLN is a combination of short-time Fourier transformation (STFT) and LSTM layers, structured in a way that allows for the effective separation of noise from the desired audio signal. To facilitate real-time application, the DTLN was converted to TensorFlow Lite format, enabling efficient execution on the Raspberry Pi 4B. The model has a size of 373,676 parameters and demonstrates rapid readiness with a loading time of 0.41 seconds. Such efficiency underscores the model's suitability for on-device acoustic signal processing. Figure 9 depicts the waveform of an audio recording in which a person's request for help is combined with the noise of propellers. The figure illustrates the audio signal before and after processing with the DTLN model, showcasing the noise reduction capabilities of the model. The SNR for this particular setup was -10.05.
Furthermore, WP6 has completed its testing phase and was successfully integrated into the TeamAware Platform. The final results, after conversion into JSON format, are sent in real-time, every second, to the platform, and the output is visualized on the map.
During the workshop held in Bursa in September 2023, and subsequent validation tests at the CERTH facilities, the ADS underwent extensive testing in a variety of scenarios. These tests encompassed both indoor and outdoor environments, and the system was evaluated at multiple distances. The ADS's performance across these diverse conditions showcased its remarkable effectiveness as a tool tailored for first responders. The ADS effectively fulfills the end-user requirements, highlighting its potential as a valuable tool in emergency situations.


