The ADS Achievements
The ADS achievements can be summarized as follows:
- An acoustic vector sensor array was designed and developed for capturing audio signals
- An accurate and beneficial audio dataset was generated for the model’s training
- A system able to recognize single and overlapping sound events with high accuracy was implemented
- A system that runs real-time on a Raspberry Pi 4B with the ReSpeaker Mic-Array
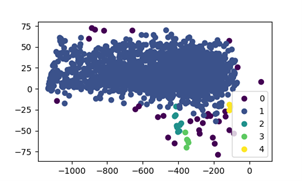
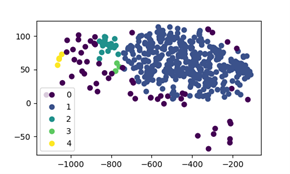
In more detail, public audio datasets (FSD50K, MIVIA) were collected and combined in order to shape a proper dataset for the model’s training. However, the fact that some of these audio samples were weakly labeled or contained wrong labels, affected the overall model’s performance. Therefore, unsupervised anomaly detection methods based on the MFCC features were applied in order to clean the data and remove the outliers. Based on each class distribution, K-means or DBSCAN algorithm was chosen. The following figures illustrate the result of K-means algorithm on male speech and traffic noise audio samples. The ones contained in 0 cluster were removed as they were detected as outliers. The final models were trained on this dataset which was proven to increase accuracy.
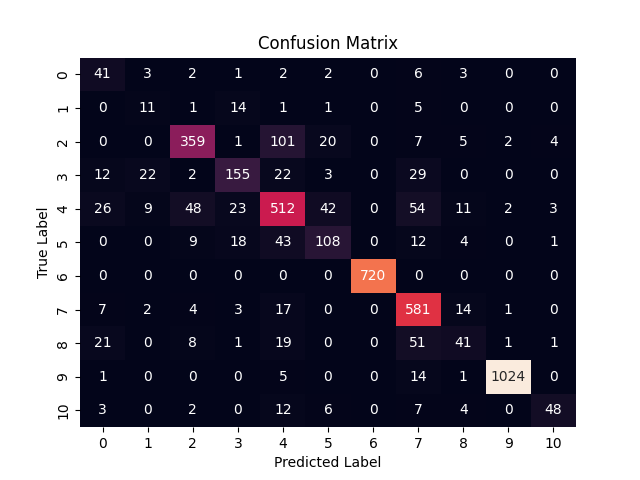
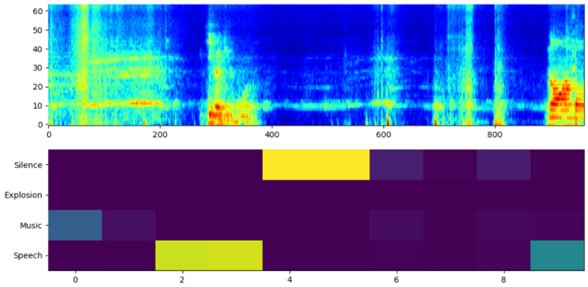
Furthermore, deep learning models were developed and trained on 11 classes for the sound event detection task. For this purpose, STFT spectrogram magnitude representations as well as mel-spectrogram energies features were extracted. DenseNet-121 and custom 2D CNN model based on YAMNet were implemented for single and overlapping sound event detection respectively. Moreover, for the needs of the overlapping sound event detection, mixup augmentation with 30% mixture was used. The final models were optimised to run on a Raspberry Pi 4B using the ReSpeaker Mic-Array and provide detection results in real-time.
Demo videos for both tasks are presented on the following videos:
